

With all the talk in the industry today regarding large language models with their encoders, decoders, multi-headed attention layers, and billions (soon trillions) of parameters, it is tempting to believe that good AI is the result of model design only. Unfortunately, this is not the case. Good AI requires more than a well-designed model. It also requires properly constructed training and testing data.
In this post, I will introduce the concept of data-centric AI, a term first coined by the folks at Snorkel AI. I’ll also introduce Snorkel Flow, a platform for data-centric AI, and show how to use it in conjunction with MinIO to create a training pipeline that is performant and can scale to any AI workload required.
Before defining data-centric AI, let’s start off with a quick review of exactly how model-centric AI works.
Model-Centric AI
Model-centric AI is an approach to artificial intelligence that focuses on improving the performance of the AI model itself. This approach prioritizes refining and enhancing the architectures and techniques used within the model to improve performance. Key aspects of model-centric AI include:
- Algorithm Development: Creating and optimizing algorithms to improve a model’s performance.
- Architecture Innovation: Designing new neural network architectures or modifying existing ones to enhance performance.
- Parameter Tuning: Adjusting hyperparameters to achieve optimal model performance.
- Training Techniques: Employing advanced training methods, such as transfer learning, fine-tuning, ensemble learning, or reinforcement learning, to improve the model.
Let’s define data-centric AI.
Data-Centric AI
Data-centric AI is an approach to artificial intelligence development that focuses on improving the quality and utility of the data used to train AI models. Rather than primarily concentrating on refining the algorithms or model architectures, data-centric AI emphasizes the importance of high-quality, well-labeled, and diverse datasets to enhance model performance. Data-centric AI operates on the premise that even with simpler models, high-quality data can significantly improve AI performance. This approach can be particularly effective when dealing with real-world applications where data is often noisy or imbalanced.
Model-centric AI is well suited for scenarios where you are delivered clean data that has been perfectly labeled. Unfortunately, this only occurs when you are working with well-known open-source datasets that are typically created for educational purposes. In the real world, data arrives raw and unlabeled. Let’s look at some real-world use cases that require greater attention to be paid to data than a model-centric AI approach would allow.
Real World Use-cases
In this section, I will review a few generic use cases that highlight the need for a data-centric approach to AI. As you review the various scenarios below, it is important to keep in mind that the data in question is very raw, and the goal is to label the data programmatically. This may sound odd and begs the question – If you have logic to label the data, then why do you need a model? Just use your “labeling logic” to make the predictions. I will address this question directly in the next section on labeling functions and weak supervision. For now, the short answer is that labeling logic is imprecise and noisy, and a model using imprecise labels will still do a better job of making predictions than using the labeling logic directly.
Statistical Data Analysis: Oftentimes, important information is buried within a document that contains important clues for labeling. For example, publicly traded companies are required by the U.S. Securities and Exchange Commission (SEC) to fill out a 10-K report annually. A 10-K contains information pertaining to financial performance: financial statements, earnings per share, and executive compensation, to name a few. In Canada, companies file an SEC Form 40-F to provide similar information. If these documents need to be manually processed to pull out information needed for model training, then that would be an arduous and error-prone process.
Keyword Analysis: Oftentimes keywords within a document are all that is needed to label the document. For example, it is common for an organization to monitor its brand on the internet if it requires a favorable public opinion to do business. These organizations should monitor the news on a daily basis, looking for groups or even individuals who are unhappy with it. This requires processing news feeds looking for mentions of the company name, and then finding keywords in the document that indicate sentiment. This may be as simple as looking for simple words such as “bad,” “terrible,” “great,” and “awesome” that indicate sentiment – but there may be domain-specific keywords that should also be used.
The Need for Subject Matter Experts: The logic needed to determine a label may not be straightforward. Rather, an expert with detailed knowledge of all the information in a piece of data may be needed to determine the correct label. Consider medical images and medical records that require the expertise of a doctor to determine the correct diagnosis.
Data Lookup: Often, an organization may have another application or database that contains additional information useful for determining the correct label. Consider a customer database that has demographic data for every customer. This could be used to determine labels for any customer-centric dataset, such as targeted advertising and product recommendations.
Based on the hypothetical examples described above, we can make a few observations. First, if the labeling described above had to be done manually, then creating the labels would be very costly and time-consuming. This is especially true when a lookup into another system is required, and a subject matter expert is needed. Subject matter experts may be hard to find and may be busy with other tasks.
A better approach would be to find a way to programmatically accomplish what was described above in a way that captures the expertise of a subject matter expert in code. This is where label functions and weak supervision come into play.
Label Functions
Label Functions are a way to capture labeling logic so that it can be programmatically applied. For example, if you start out manually labeling a dataset, you will notice that you are repeatedly doing the same thing for every record (or document) in the dataset. Apply this to our scenarios above; this could be, gleaning multiple pieces of statistical data from a document to determine a label, looking for the same keyword-label associations, doing lookups into other systems to get out-of-band data, and even the advanced logic trapped in a subject matter expert’s brain can oftentimes be expressed in a label function.
Labeling Functions (LFs) within Snorkel Flow allow for the logic described above to be programmatically captured. An LF is simply an arbitrary function that takes in a data point and either outputs a label or abstains. You can do whatever you want within an LF. If you can think of a programmatic way to label some subset of your data with a precision that’s better than random, then code it in an LF. This allows you to capture your domain knowledge.
Many LFs take a common form. For these common LFs, Snorkel Flow provides a library of no-code templates, and all you need to provide is the nugget of domain knowledge to complete it. For example, provide the specific keyword that you’re looking for – from there, Snorkel Flow will combine the template code with your nugget of information and create an executable LF. An example is shown below.
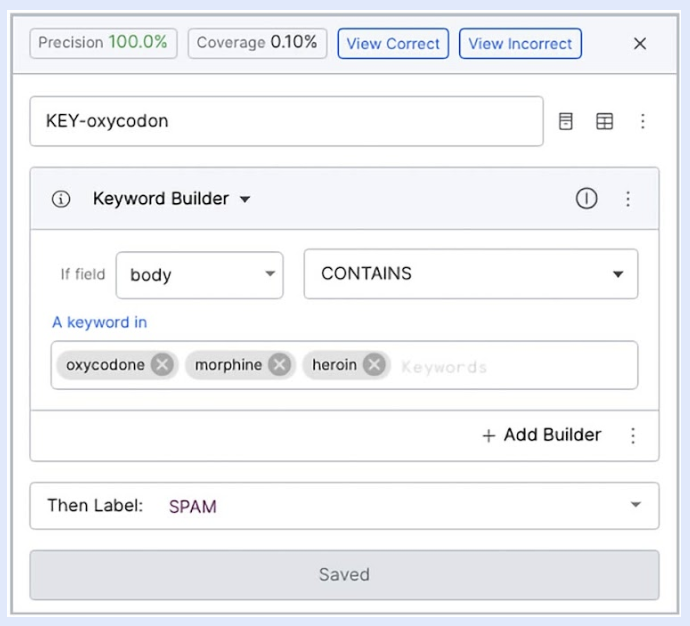
In some cases, you may want to express a very specific type of signal that doesn’t have a corresponding template yet or which uses a closed source library that only you have access to—in that case, you can use the Python SDK to define a custom LF in the Snorkel Flow integrated notebook as shown below.
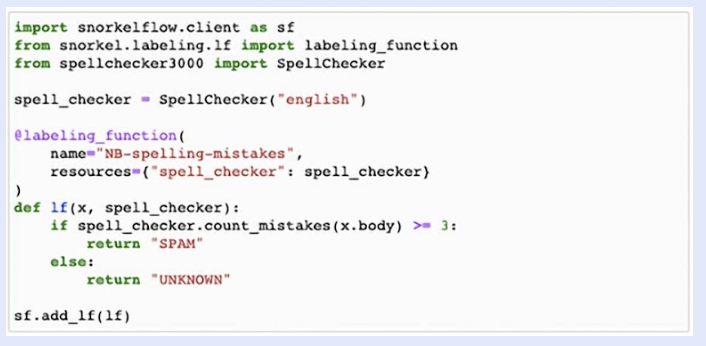
Now that we understand label functions and the various scenarios they can be used – let’s look at a complete end-to-end machine learning workflow.
Putting it All Together with MinIO
A machine learning workflow using MinIO and Snorkel Flow is shown below.
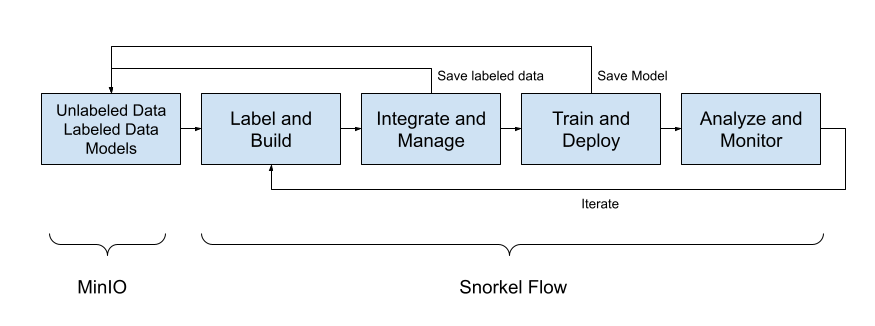
Raw Data: MinIO is the best solution for collecting and storing raw unstructured data. Additionally, if you are not working with documents and have structured data, you can use MinIO in the context of a Modern Data Lake. Check out our Reference Architecture for a Modern Data Lake for more information. MinIO also has many great tools for onboarding data. (This is done in the Ingestion Layer of our reference architecture.)
Label and Build: The Label and Build phase creates your label functions. Whether they were created via a template or handwritten by an engineer, they will be aggregated and prepared in this phase.
Integrate and Manage: Once you have all your LFs in place, they can be run to produce the labels. Consider manually labeling a small subset of your data. This manually labeled data is known as your ground truth, and you can compare the results of your LFs to your ground truth to measure their performance. Once you are ready to move on to model training, you should save a copy of your newly labeled data back to MinIO for safekeeping.
Train and Deploy: Once you have a fully labeled dataset, the next step is to train a model. You can use Snorkel Flow’s model training interface, which is compatible with Scikit-Learn, XGBoost, Transformers, and Flair, to name a few. If you prefer, you can train a custom model offline and then upload the predictions via the Snorkel Flow SDK for analysis.
Analyze and Monitor: Once a model has been trained, you will want to evaluate its performance with metrics appropriate for your problem (accuracy, F1, etc.). If the quality needs to be improved (which is nearly always the case in your initial experiments), look at where your model produces incorrect predictions. The chances are that the programmatically generated label needs to be corrected. This is data-centric AI. You are improving the model by improving the data first. Only when you get to the point where your model is producing incorrect predictions on correctly labeled data, should you consider making improvements to the model itself. Once the performance is sufficient, you can deploy the model. Consider monitoring its performance over time. It is common for model performance to drop off over time as real-world conditions change. At this point, iterate on this process to fine-tune your LFs and model.
Summary
In this post, I defined model-centric AI and introduced data-centric AI. Data-centric AI is not a replacement for model-centric AI. Data-centric AI embraces the premise that you should improve your data and its labels before trying to improve your model. This makes perfect sense if you think about it. If you try to improve your model when you have bad data you will be spinning your wheels needlessly. Your model will try to fit the bad data and labels. You will end up with a model designed for bad data. A better approach is to fix the data first and design your model with good data.
I also provided a high-level overview of data-centric AI with Snorkel Flow and MinIO. Using Snorkel Flow in conjunction with MinIO provides a way to do data experiments with a storage solution capable of holding large amounts of raw data and the results from all your experiments.
If you have any questions, be sure to reach out to us on Slack!